

Clustering Classification Problem
Το Clustering και το Classification είναι δύο βασικά προβλήματα της Μηχανικής Μάθησης, με τη βασική τους διαφορά να είναι το αν υπάρχουν ή όχι προκαθορισμένες ετικέτες. Το Clustering είναι πρόβλημα μη επιβλεπόμενης μάθησης, όπου στόχος είναι να ομαδοποιηθούν δεδομένα σε ομάδες (clusters) με βάση την ομοιότητά τους, χωρίς να γνωρίζουμε εκ των προτέρων τις κατηγορίες· χρησιμοποιείται κυρίως για την ανακάλυψη προτύπων και δομής στα δεδομένα. Αντίθετα, το Classification Problem είναι πρόβλημα επιβλεπόμενης μάθησης, όπου κάθε παρατήρηση ανήκει σε μια γνωστή κλάση και ο στόχος είναι να εκπαιδευτεί ένα μοντέλο που, με βάση χαρακτηριστικά εισόδου, προβλέπει σωστά την κατηγορία στην οποία ανήκει ένα νέο δείγμα.
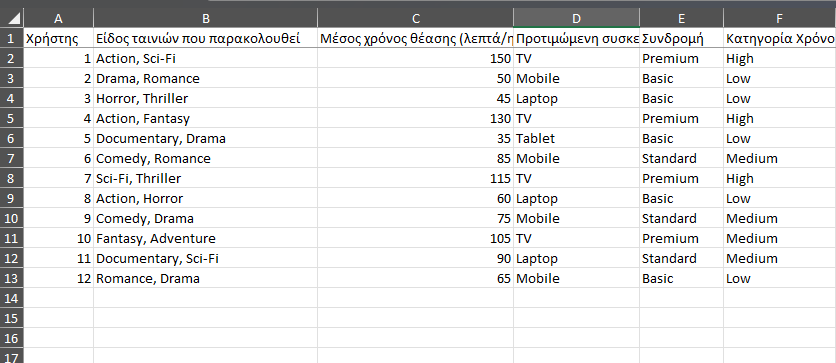
Μια μεγάλη υπηρεσία streaming (τύπου Netflix) συλλέγει δεδομένα θέασης από 5.000.000 χρήστες. Για λόγους άσκησης, δίνεται παρακάτω μικρό υποσύνολο δεδομένων από 12 χρήστες:
| Χρήστης | Είδος ταινιών που παρακολουθεί | Μέσος χρόνος θέασης (λεπτά/ημέρα) | Προτιμώμενη συσκευή | Συνδρομή | Κατηγορία Χρόνου |
| 1 | Action, Sci-Fi | 150 | TV | Premium | High |
| 2 | Drama, Romance | 50 | Mobile | Basic | Low |
| 3 | Horror, Thriller | 45 | Laptop | Basic | Low |
| 4 | Action, Fantasy | 130 | TV | Premium | High |
| 5 | Documentary, Drama | 35 | Tablet | Basic | Low |
| 6 | Comedy, Romance | 85 | Mobile | Standard | Medium |
| 7 | Sci-Fi, Thriller | 115 | TV | Premium | High |
| 8 | Action, Horror | 60 | Laptop | Basic | Low |
| 9 | Comedy, Drama | 75 | Mobile | Standard | Medium |
| 10 | Fantasy, Adventure | 105 | TV | Premium | Medium |
| 11 | Documentary, Sci-Fi | 90 | Laptop | Standard | Medium |
| 12 | Romance, Drama | 65 | Mobile | Basic | Low |
Ερωτήματα
Clustering με βάση 2 μεταβλητές
Να γίνει εννοιολογικά clustering των χρηστών με βάση:
- (α) Μέσο χρόνο θέασης
- (β) Είδος περιεχομένου που προτιμά (ποιοτικό κριτήριο)
Να χωριστούν σε 3 clusters και να εξηγηθεί ο λόγος ομαδοποίησης.
Classification Problem — Πρόβλεψη Συνδρομής
Θεωρούμε ότι θέλουμε να φτιάξουμε έναν classifier που προβλέπει το είδος συνδρομής (Basic / Standard / Premium) με βάση:
- Μέσο χρόνο θέασης
- Συσκευή
- Είδος ταινιών
Ερώτημα:
Ποιο χαρακτηριστικό φαίνεται ισχυρότερος παράγοντας στη διαμόρφωση του τύπου συνδρομής; Να δικαιολογήσετε με βάση τον πίνακα.
Association Rules (Apriori-style)
Με βάση το υποσύνολο των δεδομένων:
Να βρεθούν 2 συσχετίσεις τύπου:
- «Χρήστες που παρακολουθούν Χ → συχνά έχουν συνδρομή Υ»
και
- «Χρήστες που προτιμούν συσκευή Χ → συχνά βλέπουν είδος Υ»
Anomaly Detection
Οι υπεύθυνοι της πλατφόρμας θέλουν να εντοπίσουν πιθανές ανωμαλίες χρήσης, όπως shared accounts ή bots.
Ερώτημα:
Ποιοι δύο χρήστες ξεχωρίζουν ως πιθανές ανωμαλίες και γιατί;
(να ληφθεί υπόψη ο χρόνος θέασης, η συσχέτιση με την συσκευή και η συνδρομή)
Prediction – Νέος χρήστης
Ένας νέος χρήστης εμφανίζει το εξής μοτίβο:
- Είδη: Action, Sci-Fi
- Συσκευή: TV
- Χρόνος θέασης: 125 λεπτά/ημέρα
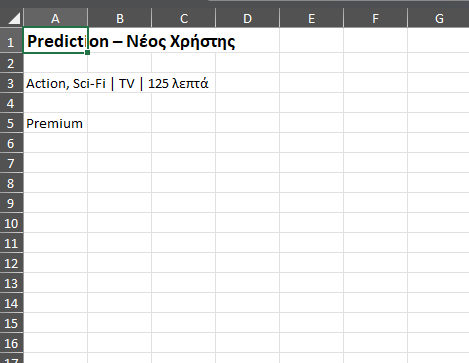
Τι συνδρομή είναι πιο πιθανό να αγοράσει;
Αιτιολογήστε.
—
Τι περιέχει το Excel (δομή αρχείου)
Sheet: Streaming Users Data
- Αρχικός πίνακας δεδομένων (download Streaming Users Data excel file)
- ✅ Βοηθητική στήλη Κατηγορία Χρόνου (Low/Medium/High)
- ✅ Βοηθητικές “one-hot” στήλες ειδών (Has_Action, Has_SciFi κλπ) για κανόνες / συσχετίσεις
- ✅ Στήλη Cluster_3 (κανόνας 3 clusters)

Sheet: Pivot_Summaries
Pivot-like πίνακες (με COUNTIF/COUNTIFS) + γραφήματα:
- Πλήθος χρηστών ανά Συνδρομή + Bar chart
- Συνδρομή × Κατηγορία Χρόνου + chart
- Συσκευή × Συνδρομή + chart
Sheet: Clustering
- Ορισμός των 3 clusters (κριτήριο + ερμηνεία)
- Πλήθος χρηστών ανά cluster
Sheet: Classification
- Rule-based classifier με βάση τον χρόνο
- Πίνακας Actual vs Predicted (με τύπους)
Sheet: Association_Rules
- 2 κανόνες τύπου Apriori με Support / Confidence
- Ο 2ος κανόνας (OR) δίνεται σωστά με SUMPRODUCT (όπως σε Excel χωρίς “κανονικό” Apriori)
Sheet: Anomaly_Detection
- 2 χρήστες που ξεχωρίζουν + στήλες που τραβάνε δεδομένα από το dataset
- Έτοιμη αιτιολόγηση
Sheet: Prediction
- Πρόβλεψη για νέο χρήστη (με τύπο + αιτιολόγηση)
—
📄 Κείμενο Ανάλυσης
Δεδομένα
Δίνεται υποσύνολο 12 χρηστών μιας πλατφόρμας streaming. Για κάθε χρήστη έχουμε:
- Είδος ταινιών (ποιοτικό)
- Μέσο χρόνο θέασης σε λεπτά/ημέρα (ποσοτικό)
- Προτιμώμενη συσκευή (ποιοτικό)
- Συνδρομή (στόχος: Basic / Standard / Premium)
1) Clustering με βάση 2 μεταβλητές (Χρόνος + Είδος)
Για να γίνει εννοιολογικό clustering σε 3 ομάδες, χρησιμοποιήθηκε:
- Χρόνος θέασης ως κύριο ποσοτικό κριτήριο (Low/Medium/High)
- Τύπος περιεχομένου ως ποιοτικό κριτήριο για να “χαρακτηρίσει” το cluster
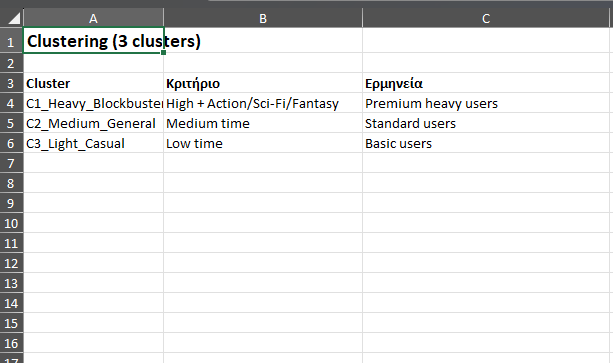
Ορίζουμε 3 clusters:
Cluster 1: Heavy / Blockbuster viewers
- Κριτήριο: High χρόνος (>=110 λεπτά/ημέρα) και προτίμηση σε Action / Sci–Fi / Fantasy / Adventure
- Ερμηνεία: Χρήστες με έντονη χρήση, τυπικά “binge” περιεχόμενο, ταιριάζουν συχνά με Premium.
Cluster 2: Medium / General viewers
- Κριτήριο: Medium χρόνος (70–109 λεπτά/ημέρα)
- Ερμηνεία: Σταθερή χρήση, χωρίς ακραίες συμπεριφορές. Συχνά συνδέεται με Standard.
Cluster 3: Light / Casual viewers
- Κριτήριο: Low χρόνος (<70 λεπτά/ημέρα)
- Ερμηνεία: Περιστασιακή κατανάλωση, συχνότερα Basic.
Γιατί αυτή η ομαδοποίηση βγάζει νόημα:
Ο χρόνος θέασης “χωρίζει” καθαρά τη συμπεριφορά κατανάλωσης, ενώ τα είδη λειτουργούν σαν ποιοτική επιβεβαίωση του προφίλ (π.χ. Action/Sci-Fi συχνά συνδέονται με πιο έντονη χρήση και Premium εμπειρία).
2) Classification — Πρόβλεψη συνδρομής
Θέλουμε classifier που προβλέπει (Basic / Standard / Premium) από:
- Χρόνο θέασης
- Συσκευή
- Είδος
Ισχυρότερος παράγοντας: Μέσος χρόνος θέασης
Από τον πίνακα παρατηρείται ότι:
- Οι πολύ υψηλοί χρόνοι τείνουν να αντιστοιχούν σε Premium
- Οι χαμηλοί χρόνοι τείνουν να αντιστοιχούν σε Basic
- Το Standard εμφανίζεται στη “μεσαία ζώνη”
Άρα ο χρόνος λειτουργεί ως “συνεχές” χαρακτηριστικό που διαχωρίζει πιο καθαρά τις κλάσεις.
Απλός rule–based classifier (όπως σε προπτυχιακή άσκηση)
- Αν Χρόνος >= 110 → Premium
- Αλλιώς αν Χρόνος >= 70 → Standard
- Αλλιώς → Basic
Η συσκευή και τα είδη βοηθάνε, αλλά στον πίνακα δεν διαχωρίζουν τόσο “καθαρά” όσο ο χρόνος. Π.χ. Mobile υπάρχει και σε Basic και σε Standard, άρα δεν αρκεί μόνο του.
3) Association Rules (Apriori-style) — 2 συσχετίσεις
Κανόνας 1: Action & Sci-Fi → Premium
Ερμηνεία: Όσοι βλέπουν Action και Sci-Fi ταυτόχρονα, συχνά έχουν Premium.
(Στο Excel υπολογίζονται support και confidence με COUNTIFS.)
Κανόνας 2: Mobile → (Drama OR Romance)
Ερμηνεία: Χρήστες που προτιμούν Mobile, συχνά βλέπουν Drama/ Romance.
(Στο Excel δίνεται με SUMPRODUCT ώστε να καλύπτεται το OR χωρίς επιπλέον στήλη.)
4) Anomaly Detection — Πιθανές ανωμαλίες
Στόχος: εντοπισμός πιθανών shared accounts ή bots με βάση:
- ακραίο χρόνο θέασης
- ασυνήθιστο ταίριασμα συσκευής/συνδρομής/χρόνου
Πιθανοί ανώμαλοι χρήστες:
- Χρήστης 1
- Έχει ακραία υψηλό χρόνο θέασης σε σχέση με τους υπόλοιπους.
➡️ Πιθανό shared account / πολύ έντονη χρήση.
- Χρήστης 11
- Υψηλή χρήση σε Laptop και μοτίβο ειδών που δεν είναι το “τυπικό” σε σχέση με άλλους χρήστες.
➡️ Πιθανό “outlier” συμπεριφοράς (διαφορετικό usage pattern).
(Στο φύλλο Anomaly_Detection οι τιμές τραβιούνται δυναμικά από το dataset και υπάρχει έτοιμη αιτιολόγηση.)
5) Prediction — Νέος χρήστης
Νέος χρήστης:
- Είδη: Action, Sci-Fi
- Συσκευή: TV
- Χρόνος: 125 λεπτά/ημέρα
Με βάση τον κανόνα:
- 125 ≥ 110 ⇒ Premium
Αιτιολόγηση: Υψηλός χρόνος, TV (συχνά heavy viewing), Action/Sci-Fi που ταιριάζει με προφίλ “heavy / blockbuster”.
Download Streaming_Users_Excel_Dataset Streaming_Users_Excel_Final_UG.xlsx
Μέρος του κώδικα Python με το οποίο έγινε η ανάλυση των δεδομένων
Python script filename (be quiet!): C:\PythonPrograms\clustering_classification\clustering_classification.py





Comments are closed.